Ops Manager Overview¶
On this page
Overview¶
MongoDB Ops Manager is a service for managing, monitoring and backing up a MongoDB infrastructure. In addition, Ops Manager allows Administrators to maintain a server pool to facilitate the deployment of MongoDB.
Ops Manager provides the services described here.
Monitoring¶
Ops Manager Monitoring provides real-time reporting, visualization, and alerting on key database and hardware indicators.
How it Works: A lightweight Monitoring Agent runs within your infrastructure and collects statistics from the nodes in your MongoDB deployment. The agent transmits database statistics back to Ops Manager to provide real-time reporting. You can set alerts on indicators you choose.
Automation¶
Ops Manager Automation provides an interface for configuring MongoDB nodes and clusters and for upgrading your MongoDB deployment.
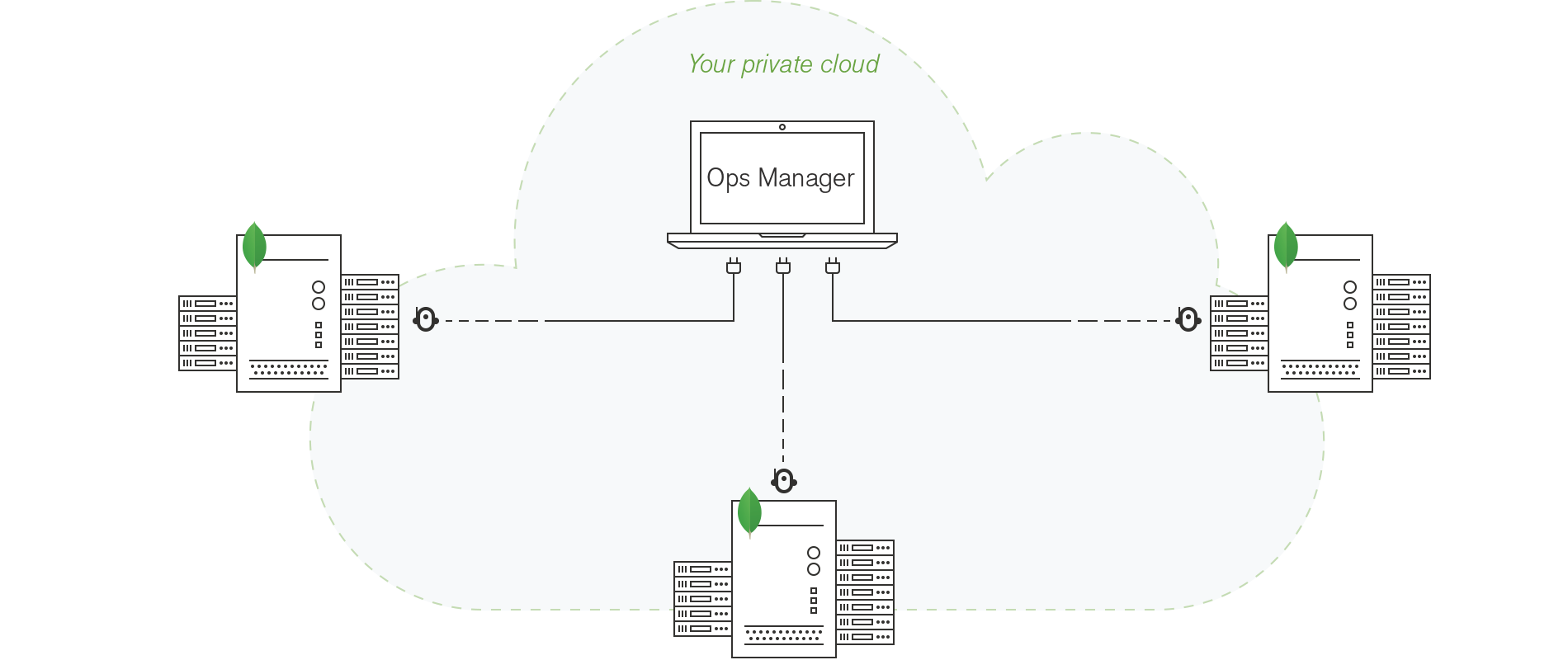
How it Works: Automation Agents on each server maintain your deployments. The Automation Agent also maintains the Monitoring and Backup agents and starts, restarts, and upgrades the agents as needed.
Automation allows only one agent of each type per machine and will remove additional agents. For example, when maintaining Backup Agents, automation will remove a Backup Agent from a machine that has two Backup Agents.
Backup¶
Ops Manager Backup provides scheduled snapshots and point-in-time recovery of your MongoDB replica sets and sharded clusters.
How it Works: A lightweight Backup Agent runs within your infrastructure and backs up data from the MongoDB processes you have specified.
Note
Only sharded clusters or replica sets can be backed up. To back up a standalone mongod process, you must first convert it to a single-member replica set.
Data Backup¶
When you start Backup for a MongoDB deployment, the agent performs an initial sync of the deployment’s data as if it were creating a new, “invisible” member of a replica set. For a sharded cluster the agent performs a sync of each shard’s primary and of each config server. The agent ships initial sync and oplog data over HTTPS back to Ops Manager.
The Backup Agent then tails each replica set’s oplog to maintain on disk a standalone database, called a head database. Ops Manager maintains one head database for each backed-up replica set. The head database is consistent with the original primary up to the last oplog supplied by the agent.
Backup performs the initial sync and the tailing of the oplog using standard MongoDB queries. The production replica set is not aware of the copy of the backup data.
Backup uses a mongod with a version equal to or greater than the version of the replica set it backs up.
Backup takes and stores snapshots based on a user-defined snapshot retention policy. Sharded clusters snapshots temporarily stop the balancer via the mongos so that they can insert a marker token into all shards and config servers in the cluster. Ops Manager takes a snapshot when the marker tokens appear in the backup data.
The procedures used to reduce the storage space required to store a snapshot depend on where it is stored, as described in the following table:
| Snapshot Store | Description |
|---|---|
| MongoDB blockstore | Each successive snapshot stores only the differences from the previous snapshot. Compression and block-level de-duplication reduce the size of snapshot data. |
| AWS S3 bucket | Each successive snapshot stores only the differences from the previous snapshot. Compression and block-level de-duplication reduce the size of snapshot data. |
| File system store | Depending on the configuration, compression reduces the size of the snapshot data. |
All snapshots represent a full backup. See Backup Configuration Options for more information about backup configurations.
Data Restoration¶
Ops Manager Backup lets you restore data from a scheduled snapshot or from a selected point between snapshots. For sharded clusters you can restore from checkpoints between snapshots. For replica sets, you can restore from selected points in time.
When you restore from a snapshot, Ops Manager reads directly from the snapshot storage and transfers files either through an HTTPS download link or by sending them via HTTPS or SCP.
When you restore from a checkpoint or point in time, Ops Manager first creates a local restore of a snapshot from the snapshot storage and then applies stored oplogs until the specified point is reached. Ops Manager delivers the backup via the same HTTPS or SCP mechanisms. To enable checkpoints, see Enable Cluster Checkpoints.
The amount of oplog to keep per backup is configurable and affects the time window available for checkpoint and point-in-time restores.
Server Pool¶
Ops Manager Server Pool allows Ops Manager users with administrative privileges, i.e. Ops Manager Administrators, to maintain a pool of provisioned servers that already have Automation Agents installed. When users in a group want to create a new MongoDB deployment, they can request servers from this pool to host the MongoDB deployment.
For details, see Provision Servers for the Server Pool.