- Back Up and Restore Deployments >
- Back up MongoDB Deployments >
- Backup Flows
Backup Flows¶
On this page
Introduction¶
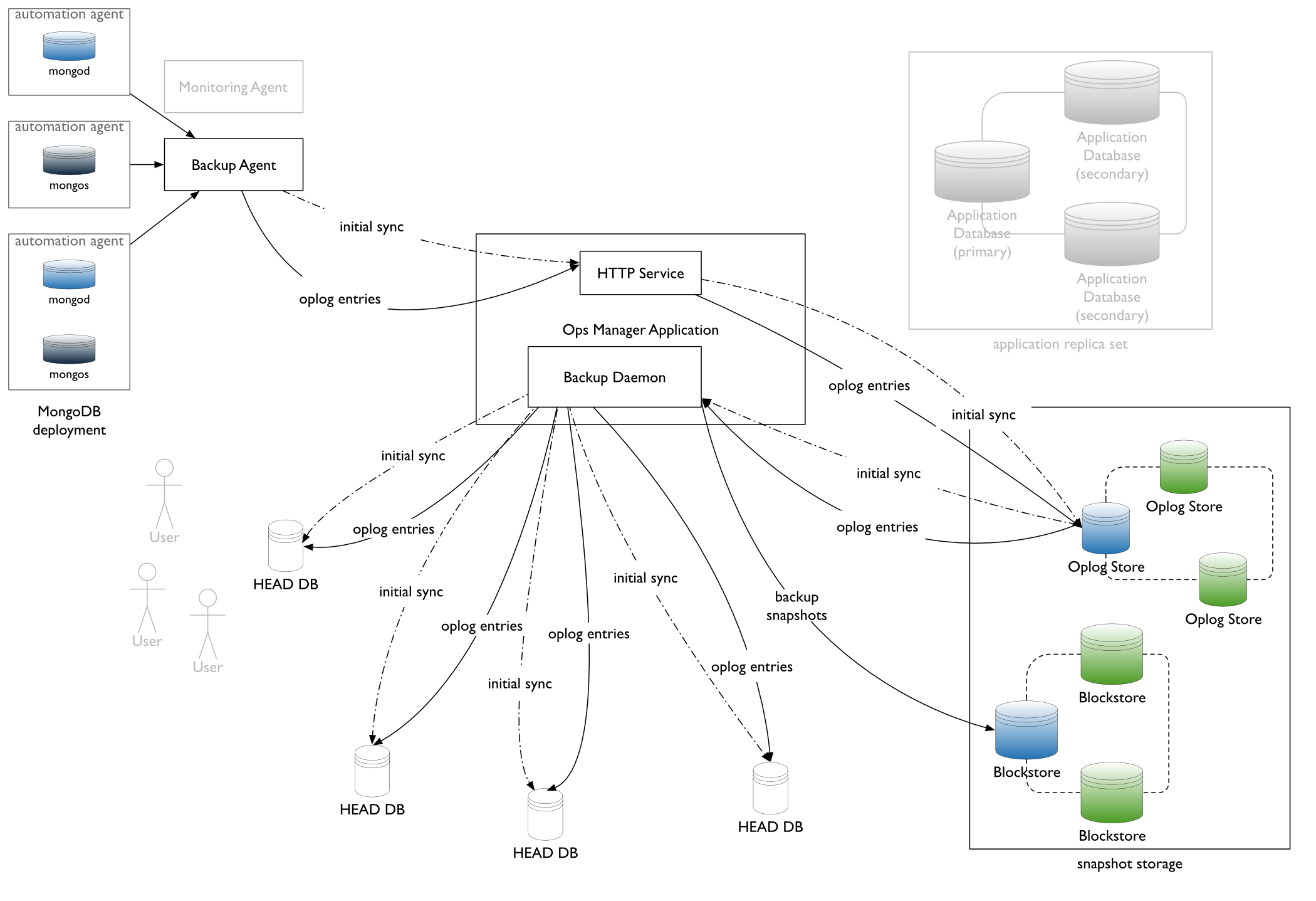
Ops Manager backups, once started, are an ongoing and continuous process. Data is continually backed up as long as the backup remains synchronized with the database. This process works like the process used to replicate data in a replica set to secondary. The Backup process:
- Performs an initial sync to back up all of the data in its current state.
- Takes scheduled snapshots to keep the database backup current.
- Constantly monitors the oplog and adds its operations to the latest backup to keep its copy of the data current.
The backup process works in this manner using either database-based (blockstore) or file-based (file system) backup storage.
Snapshot Storage¶
Snapshots¶
The backup process takes a snapshot of the data directory of the backed-up deployment as often as specified by the snapshot schedule. This snapshot is transferred to snapshot storage.
For a sharded cluster, the backup process takes a snapshot of each shard and of the config servers. The backup process can also use checkpoints to permit restores at moments between snapshots. You must first enable checkpoints.
Blockstores¶
File Systems¶
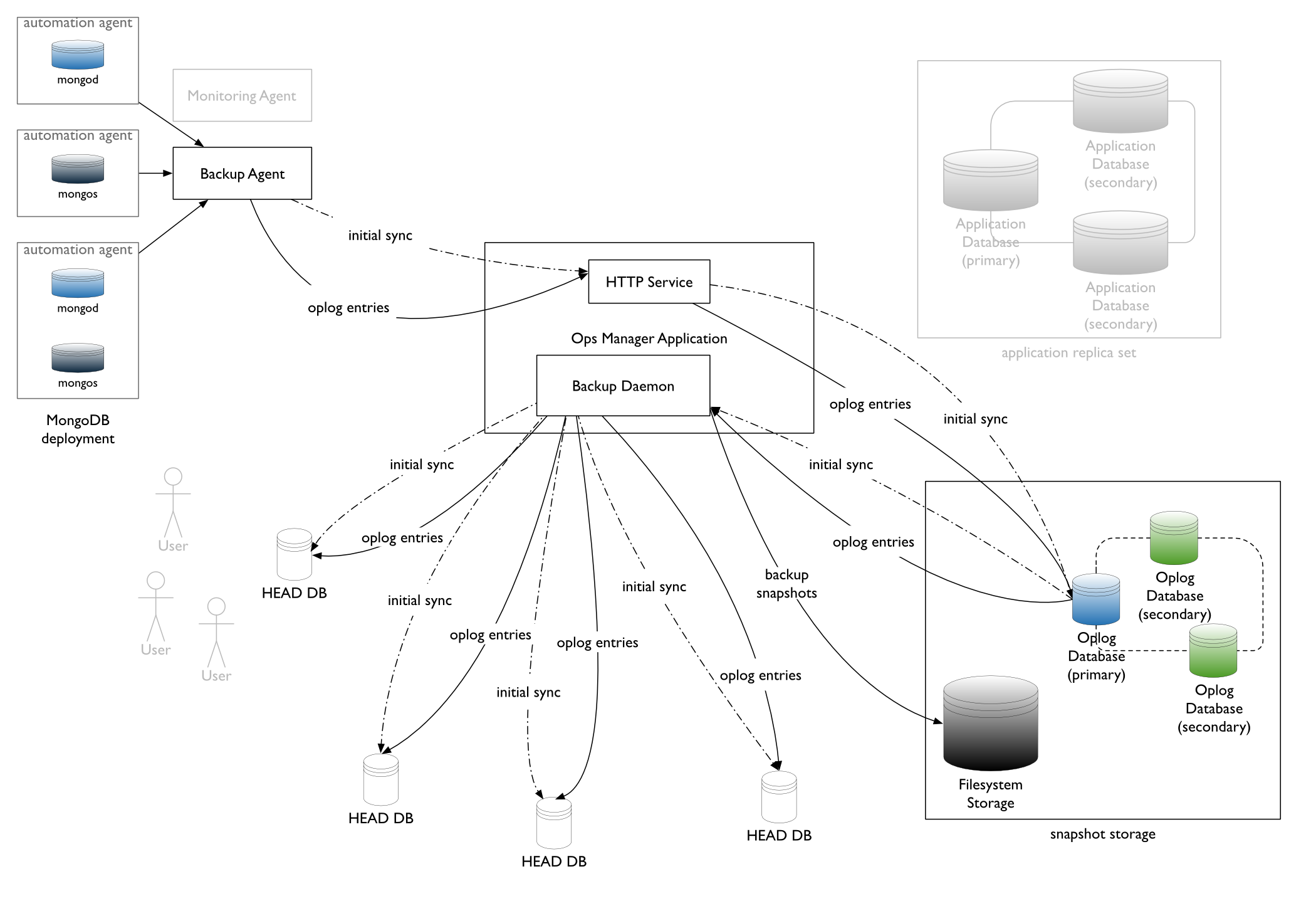
File System storage gives you full control over your data, allowing you to reduce the number of MongoDB instances you need to run and enabling you to take advantage of existing storage infrastructure. With filesystem storage, you can access the backed-up data files using standard filesystem utilities, rather than having to retrieve them through the Ops Manager interface.
With filesystem storage, you can select any mountable filesystem to which Ops Manager writes the snapshots.
If you use file system snapshot storage and use multiple Ops Manager instances (including those activated as Backup Daemons), all Ops Manager instances must have the same view of the file system snapshot storage. You can achieve this through a Network File System (NFS) application or something similar.
Important
If the Ops Manager instances do not share the same view of file system snapshot storage, Backup restores will not be possible and Ops Manager will not be able to remove expired snapshots.
Operation Logs¶
When a new Blockstore is added, that Blockstore integrates an oplog store into its database.
When a new file system store is created, you are prompted to create an oplog store.
Once an oplog has been created for a snapshot store, adding any additional snapshot stores does not require another oplog.
Backup States¶
A backup job defines how much and how often data is backed up. There are three states for a backup job: active, inactive or stopped.
| State | Retain Old Snapshots | Create New Snapshots | Apply Oplogs |
|---|---|---|---|
Active |
Yes | Yes | Yes |
Stopped |
Yes | No | No |
Inactive |
No | No | No |
Once backups are active for a Group, they run without further intervention until they are stopped or terminated. The operator can change the state of a backup in the following ways:
| Initial State | Desired State | Method |
|---|---|---|
Active |
Active after Initial Sync |
Click Start. |
Active |
Stopped | Click Stop. |
Stopped |
Active after Initial Sync |
Click Restart. |
Stopped |
Inactive | Click Terminate. Warning Terminate deletes all retained backups. |
Important
You may receive a Resync Required alert
for your backup jobs. This may require you to Resync a Backup.
This is not a different state, but a triggering of
a new Initial Sync. The backup job, once Initial
Sync completes, becomes Active again.
Initial Sync¶
Initial Sync is an interim state between Inactive and Active. Its activities are exposed to the operator to keep them informed that the process is in progress.
Transfer of Data and Oplog Entries¶
When you start a backup, the Backup Agent streams your deployment’s existing data to Ops Manager in batches of documents, totaling roughly 10 MB each, called slices. Slices contain only the data as it existed when you started the backup.
While transferring the data, the Backup Agent tails the oplog and streams the oplog updates to Ops Manager. Ops Manager then stores the oplog entries in the oplog database for later processing offline.
Building the Backup¶
When Ops Manager has received all of the slices, it creates a local database on its server and inserts the documents that were captured as slices during the initial sync. Ops Manager then applies the oplog entries from the oplog store.
Ops Manager then validates the data. If there are missing documents, Ops Manager queries the deployment for the documents and inserts them. A missing document could occur because of an update that caused a document to move during the initial sync.
Once Ops Manager validates the accuracy of the data directory, it has completed the initial sync process and proceeds to routine operation.
Initial Sync Phases¶
Backups go through a series of phases during backup. The first backup
is called the initial synchronization (initialSync). If you click
the Backup button, you are presented with the list of
backup jobs in progress. During initialSync, they proceed through
these phases in the following order:
| Phase | Description | Measure of Progress |
|---|---|---|
starting |
Waiting phase until Ops Manager receives sync slices. | None |
transferring |
Shows progress one namespace at a time. |
|
building |
Ops Manager has started building the deployment Note As of Backup Agent 4.0 and Ops Manager 2.0, this happens in the
background during the |
The percentage of the entire HEAD database that has been
built. |
applying oplogs |
Ops Manager has completed building the HEAD database. Ops Manager is
applying the oplog entries to catch up with the customer’s oplog
at the point that the previous phase completed. |
The percentage of slices currently applied. |
fetching missing documents |
Ops Manager queries the customers deployment for documents missed
during the building and applying oplogs phases. |
The percentage of slices currently applied. |
creating indexes |
Ops Manager creates all the indexes of the customer’s deployment. |
|
complete |
The backup initialSync job has completed. |
Routine Operation¶
The Backup Agent tails the deployment’s oplog and routinely batches and transfers new oplog entries to the HTTP Service, which stores them in the oplog store. The Backup process applies all newly-received oplog entries in batches to its local copy of the backed-up deployment.
Restores¶
When a user requests a snapshot, a backup process retrieves the data from the snapshot storage and delivers it to the requested destination.
See also
Restore Overview for an overview of the restore process.
Grooms¶
Groom jobs perform periodic “garbage collection” on the snapshot storage to reclaim space from deleted snapshots. A scheduling process determines when grooms are necessary.